Amazon CodeGuru는 코드를 넣으면 코드를 분석하고 결과를 출력하는 서비스이다. 특히 AWS API를 사용하는 코드를 분석할 때 뛰어난 성능을 보여준다고 한다. CodeGuru 서비스는 CodeGuru Reviewer와 Profiler로 나뉘는데, Reviewer는 안정성(보안 취약점 식별, Best practice 제안), Profiler는 퍼포먼스에 초점을 둔 서비스로 볼 수 있다. 내가 관심있는 기능은 Reviewer이기 때문에, 이번 포스트에서는 Reviewer에 한정하여 작성한다.
CodeGuru로는 Java와 Python 코드를 분석할 수 있으며, AWS CodeCommit, Bitbucket, GitHub, GitHub Enterprise Server의 리포지토리는 Reviewer와 연동하여 사용이 가능하다. 문제는 우리 팀은 리모트 리포지토리로 GitLab을 사용하고 있어서 리포지토리와 직접 연동이 어렵다는 점이다. 하지만 해결책은 있기 마련이어서, GitLab에서 제공하는 Repository mirroring 기능을 활용하면 GitLab 리포지토리와 AWS CodeCommit 리포지토리를 연동할 수 있고, AWS 블로그에서 CodeGuru Reviewer CLI를 사용하여 CI/CD Pipeline을 설정하는 방법도 찾을 수 있었다.
GitLab Repository Mirroring(AWS Codecommit)
AWS CodeCommit 리포지토리는 AWS 루트 계정에 종속된 자원이므로, 아래와 같이 IAM을 통한 권한 설정이 선행되어야 한다.
IAM User에 AWSCodeCommitPowerUser 정책을 붙인다.
해당 User의 Security credentials에 가서 HTTPS Git credentials for AWS CodeCommit에서 Git credential을 생성한다.
이후 CodeCommit 리포지토리를 생성하고 그 URL을 복사한다. 주의할 점은 CodeGuru는 2022년 9월 현재 Seoul 리전에서 서비스되지 않기 때문에 CodeGuru가 목적일 경우 다른 리전에 생성하여야 한다.
CodeCommit 리포지토리의 URL과 CodeCommitPowerUser 정책이 붙은 IAM User의 Git credential 2가지 정보가 있다면 비로소 GitLab에서 Reporitory mirroring 기능을 설정할 수 있다.
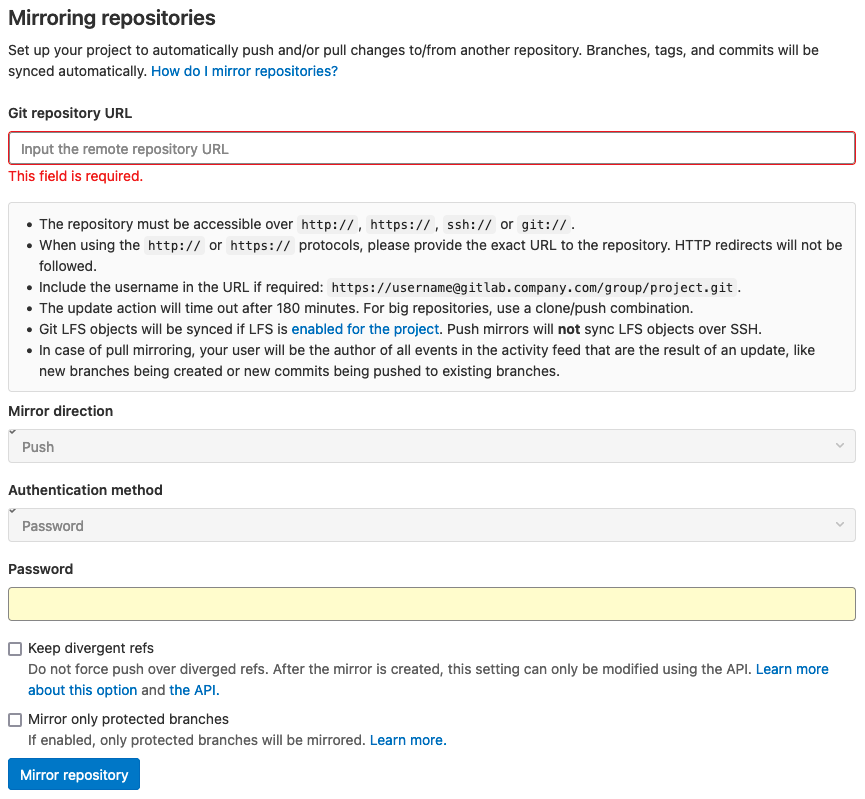
GitLab 리포지토리의 Setting > Repository > Mirroring repositories에서 URL을 입력하는데, 앞서 언급한 2개의 정보를 조합하여야 한다. CodeCommmit 리포지토리 URL은 https://git-codecommit.REGION_NAME.amazonaws.com/v1/repos/REPOSITORY_NAME 형태인데, HTTP로 Git을 사용하기 위해 프로토콜 뒤에 Git Credential의 username을 추가하고 @를 추가해야 한다. 즉, 아래와 같은 형태로 URL을 입력한다 https://GIT_CREDENTIAL_USERNAME@git-codecommit.REGION_NAME.amazonaws.com/v1/repos/REPOSITORY_NAME 이후 아래 필드에 Password를 입력하고 저장하면 GitLab 리포지토리와 CodeCommit 리포지토리 간 Mirroring 관계가 성립된다.
CodeGuru Reviewer CLI
고민했지만 AWS 블로그의 자세한 설명 이상으로 좋은 설명을 쓸 자신은 없어서 링크로 대신하기로 했다.
Jenkins 인스턴스에 CodeGuru Reviewer CLI(AWS CLI 아님)를 설치하고 권한을 설정하는 것이 주요 내용으로, CLI를 통해 지정한 위치에 output 파일이 생성되어 분석 결과를 확인하거나 결과값에 따라 파이프라인 분기를 설정하는 방식이다. 다만 CLI를 사용할경우 CodeGuru Console에서는 관련 내용을 확인할 수 없다는 단점이 있다.
AWS에서 제공하는 서비스인 WAF는 Web Application Firewall의 약자이지만, WAF라는 용어는 AWS에서 새로 만든 것은 아니다. 따라서 WAF, 그 이전에 Firewall이 무엇인지 아주아주 간략하게나마 이해할 필요가 있다.
Firewall(이하 방화벽)은 일반 인터넷과 내부 네트워크를 분리하는 HW/SW의 조합으로, 패킷을 허용 또는 차단하는 방식으로 동작한다. 최초의 방화벽은 패킷의 정보(IP 주소, 포트 번호, ACK 비트 등)와 정해진 정책에 따라 패킷을 필터링하는 기능을 수행하였으나, 점차 다양한 방향으로 발전하였다.
이 중 애플리케이션이나 서비스에 적용되는 L7 트래픽을 제어하는 방화벽을 Appplication Firewall이라고 불린다. 따라서, WAF는 웹 애플리케이션에 적용되는 Application Firewall을 말한다.
AWS WAF
AWS WAF는 규칙 기반(Rule-based)으로 특정 AWS resource의 인/아웃바운드 트래픽을 제어할 수 있는 서비스이다.
WAF로 제어 가능한 AWS resource는 아래와 같다.
Amazon CloudFront distribution
Amazon API Gateway REST API
Application Load Balancer
AWS AppSync GraphQL API responds to HTTP(S) web requests
Web ACL, Rule, Rule Group
WAF는 일종의 규칙 목록인 Web ACL을 관리할 resource에 연결하는 방식으로 동작한다. Web ACL은 여러 개의 Rule을 가질 수 있으며, 사용자는 다양한 Statement를 조합하여 Rule이 원하는 대로 동작하도록 구성할 수 있다. 또, 여러 개의 Rule을 Rule Group이라는 resource로 묶어서 관리할 수 있는데, Web ACL 역시 Rule들의 집합이라 볼 수 있으므로 Rule Group과 Web ACL의 관계는 처음 이해할 때 개인적으로 굉장히 헷갈리는 부분이었다.
AWS resource에 연결된 Web ACL은 WAF 관점에서 해당 resource를 추상화한 인터페이스로 볼 수 있다. 즉, 어떤 Web ACL에 어떤 규칙을 추가하는 것은 곧 그 Web ACL이 연결된 AWS resource에 그 규칙을 적용하는 것과 같다.
반면, Rule Group은 함께 사용되면 편리한 Rule들을 한 번에 적용하기 위한 관리 단위로, Rule Group을 AWS resource에 적용하기 위해서는 Web ACL에 이를 ‘Rule Group을 참조하는 Rule’ 형태로 추가하여 사용한다.
다만 Web ACL과 AWS resource의 대응 관계는 1:N으로, 하나의 resource에는 하나의 Web ACL만 연결할 수 있지만, 하나의 Web ACL을 여러 resource에 연결하여 재사용하는 것은 가능하다. (단, CloudFront Distribution에 연결된 Web ACL은 다른 종류의 resource들에 연결할 수 없다.)
Web ACL Capacity Unit(WCU)
모든 Rule은 전부 그 복잡도에 따라 사용하는 컴퓨팅 파워의 양을 나타내는 척도를 갖는데, 이를 WCU라 한다. 각 Web ACL은 1500의 WCU 상한선(Support 요청을 통한 상향 조정은 가능)을 가지므로, 이를 고려하여 resource 관리 체계를 구성하여야 한다.
Rule Group을 최초 생성 시 변경 불가능한 WCU 상한선(Capacity)을 지정하여야 하는데, Rule Group이 갖는 Rule들의 WCU 총합(Used Capacity)은 (당연하게도) Capacity를 초과할 수 없다.
Web ACL에 Rule Group을 추가하게 되면 Rule Group의 Capacity(Used Capacity 아님)가 Web ACL의 WCU 사용량을 잡아먹는다. 따라서 Rule Group의 Capacity를 필요 이상으로 크게 생성하면 WCU 상한선을 넘겨서 Rule Group을 다시 생성하여야 하므로, 적정 수준의 Capacity를 설정하는 것이 바람직하다.
그간 구현했던 모든 회로를 합쳐서 컴퓨터를 완성하는 과정이다. 04장에서 기계어와 어셈블리에 대해 배우고 이를 작성하고 테스트하는 과제를 하면서 01, 02, 03장에서 배운 내용에서 바로 이어지지 않는다는 느낌이 들었는데, 이번 장을 진행하면서 그 빈 부분을 채울 수 있었다.
여태까지의 흐름대로라면 두 장을 하나로 합치거나 04장과 05장의 순서가 바뀌는게 맞지 않나 싶지만, 05장에서 구현하는 회로들이 어떤 방식으로 작동하는지, 또 어떤 역할을 수행하는지를 04장에서 배우지 않았다면 안 그래도 어려운 이번 장에서 더 큰 벽을 느끼기 때문에 순서를 이렇게 구성한 것으로 보인다.
Project
Memeory, CPU, Computer 3개의 칩을 구현하는 프로젝트가 주어진다.
Memory
이 칩은 데이터를 읽고 쓰는 저장 장치의 역할을 수행하면서 출력 장치를 주소공간에 mapping하여 추상화하는 역할을 수행한다. 이렇게 두 개의 역할을 수행함에도 칩의 입/출력 명세는 굉장히 단순한데, 15비트짜리 주소 정보를 입력받은 뒤, 해당 주소에 위치하는 16비트짜리 명령어를 반환하도록 구성하면 된다. 이처럼 단순한 명세를 사용하지만 주소 공간을 분리하여 역할을 다르게 설계함으로서 임의의 데이터 저장 기능과 출력장치 제어 기능을 구현하는 것이 굉장히 인상적이었다.
입력 주소 정보가 15비트이므로, 해당 칩은 최대 2^15 = 0x8000 ~= 32K(bit)의 정보를 저장할 수 있어야 한다. 하지만 저자는 레지스터를 아래와 같이 사용하도록 구성하였고, 0x6001번 ~ 0x7FFF번 레지스터는 사용하지 않는다.
Address Area
Area Size(dec)
Area Size(hex)
Description
0x0000 ~ 0x3FFF
2^14
0x4000
RAM
0x4000 ~ 0x5FFF
2^13
0x2000
Screen memory mapping space
0x6000
1
0x0001
Keyboard memory mapping space
0x6001 ~ 0x7FFF
2^13 - 1
0x1FFF
N/A
따라서 실제로 필요한 데이터 저장 공간은 레지스터 0x4000 + 0x2000 + 0x0001개로 구성할 수 있다. 이전 챕터에서 구현한 RAM16K(레지스터 0x4000개)와 내장된 Screen(레지스터 0x2000개, 이전에 구성한 RAM8K(16bit)와 같은 역할을 하지만, 테스트 시 스크린 출력값을 확인할 수 있는 환경이 구성되어 있으므로 대신 사용한다), Keyboard(레지스터 0x0001개, Register와 같은 역할) 3개의 칩을 조합하여 구성한다.
CPU
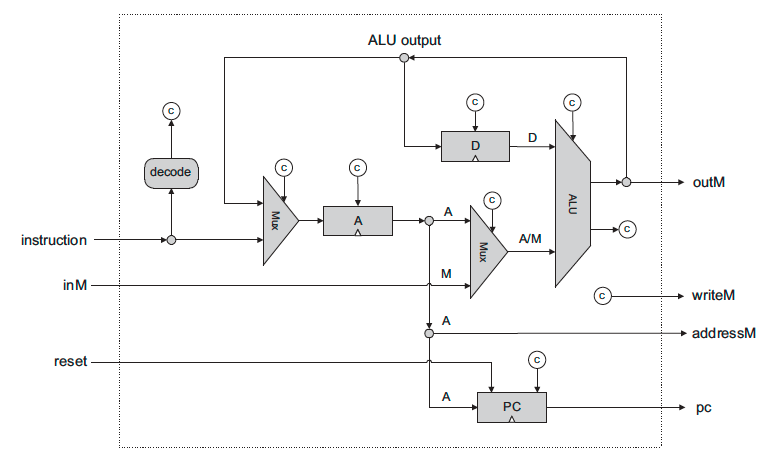
CPU는 명령어를 입력받아 이를 수행하는, 컴퓨터에서 가장 핵심이 되는 부품이다. 02장에서 왜 이런 연산이 필요한지 그 이유는 모르는 채로 과제대로 구현했던 논리들이 04장에서 배운 기본적인 16비트 명령어들에 대응한다는 점을 알게 되었을 때는 감동스럽기까지 했다. 02장에서 구현한 ALU와 03장의 PC(Program Counter), 그리고 04장에서 배운 D와 A, 두 개의 레지스터를 조합하여 구성할 수 있었다.
Computer
구현한 Memory와 CPU를 사용하여 reset 신호만 받아서 .hack 확장자의 어셈블리 프로그램을 실행할 수 있는 플랫폼이다. 말이 칩이지 입력이라고는 달랑 1비트짜리 reset 하나에 출력은 아예 없는 것이 드디어 컴퓨터에 가까운 무언가가 등장했다고 느껴졌지만, 이를 구현하는 과정이 굉장히 막막할 뻔했다. 다행히 책에서 구조를 다 설계해줘서 그동안 구현한 칩을 책에 나온대로 이어붙이기만 하면 실제로 명령어를 실행할 수 있는 컴퓨터의 구조를 만들어볼 수 있었다.
Computer는 ROM32K라는 Built-in 칩에 존재하는 명령어를 PC가 정해주는 순서대로 수행한다. ROM32K 칩은 load 명령을 사용하여 .hack 파일의 값을 불러오는 기능을 내장한, 읽기 전용의 메모리이다. 만약 reset이 발생하면 ROM을 제외한 모든 레지스터(CPU 레지스터와 RAM, PC)들의 값이 0으로 초기화되면서 Computer의 상태가 초기화된다.
Debugging
CPU 칩을 테스트하는 중, 제공된 테스트 중 CPU.tst는 통과하였으나 CPU-external.tst는 실패하였다. 뭐가 문제인지 확인해보았으나, 아무리 봐도 테스트 케이스가 잘못된 것으로 보여서 코드가 아니라 케이스를 수정해버리고 넘어갔다.(언제나 그렇듯이, 이렇게 문제를 해결하면 망한다.)
이후 Computer 칩을 완성하고 Add, Max, Rect라는 3개의 테스트 프로그램을 사용한 테스트를 진행하였다. Add와 Max는 통과하였으나, Rect를 통과하지 못해서 무엇이 문제인지 오랫동안 고민하였다. Add와 Max에서는 프로그램 이름 그대로의 산술 연산을, Rect에서는 스크린 출력을 테스트하므로, Computer 칩이 출력 장치를 제어하는 로직이 잘못된 것으로 의심하였다. 하지만 Computer는 Memory 칩을 기반으로 동작할 뿐 직접 출력 장치를 제어하는 논리는 가지고 있지 않고, Memory 칩은 이전에 데이터 저장 뿐만 아니라 입/출력 제어 역시 정상적으로 테스트를 통과했다.
디버깅을 위해 .cmp 파일과 .out 파일을 비교한 결과, D 레지스터가 업데이트되지 말아야 하는 상황에서 D 레지스터의 값이 덮어씌워지는 것을 확인할 수 있었다. 즉, 윗 문단의 CPU칩의 구현에서 D 레지스터의 값을 업데이트하는 논리에 오류가 있었는데 그 동안의 테스트에서 한 번도 문제점을 일으키지 않았던 것이다. 관련 오류를 수정하니 내 맘대로 뜯어고쳤던 CPU-external 테스트에 실패하였고, CPU-external.cmp를 초기값으로 수정하니 정상적으로 테스트를 정상적으로 통과하였다. 역시 검증된 테스트 케이스를 마음대로 고치는 건 좋은 결말로 이어질 수가 없는 법이다. CPU에서 발생한 문제가 해결되니 이를 기반으로 하는 Computer 칩에서도 문제가 해결되어 모든 테스트를 성공적으로 마칠 수 있었다.
scp는 Secure Copy의 약어로, 원격 호스트에 파일을 전송하는 수단이다. SSH를 사용하기 때문에 통신 탈취 등으로부터 안전하다.
rsync
rsync는 Remote Sync의 약어로, 마찬가지로 원격 호스트에 파일을 전송하는 수단이다. 하지만 두 파일 간 차이(difference)만을 전달하는 알고리즘을 사용하기 때문에, 대부분의 경우에 보다 효율적인 파일 전송이 가능하다. 또, SCP에 비해 훨씬 다양한 옵션을 제공하기 때문에 이를 활용하여 보다 다양한 작업을 수행할 수 있다.
하지만 rsync가 scp에 비해 반드시 우월하다고는 볼 수 없는데, rsync 자체는 암호화되지 않은 평문으로 데이터를 전송하기 때문에, 보안성을 위해서 SSH를 사용한 암호화를 사용(--rsh=ssh 옵션을 추가)하여야 한다. 반면 scp는 항상 SSH 기반 통신을 수행하기 때문에 단순하거나 가벼운 작업을 실행할 경우에는 scp를 사용하여 파일을 전송하는 것이 편리하다.
4장에서는 기계어를 통해 CPU가 어떤 방식으로 가장 간단한 프로그램을 실행하는지를 배웠다. 컴퓨터과학 태동기에 어쩌다가 천공 카드를 사용하여 프로그램을 작성하게 된 것인지 이해하게 되었다.
Instruction과 Assembly
CPU가 수행하는 모든 작업은 본질적으로 명령어(Instruction)에 따라 데이터를 처리하는 것이다. 즉, 모든 프로그램은 결국 실행하는 CPU가 따르는 명령어 집합(Instruction set)에 정의된 기본 명령어의 조합 형태로 실행되는 것이다.
최초의 프로그램은 이러한 명령어 집합을 직접 사용하여 CPU의 작업을 정의했을 것이나, 매우 불편하고 실수의 여지가 높다. 이 때 명령어와 메모리 주소 등 필요한 항목에 이를 나타내는 기계어(이진 입력)와 1:1로 대응하는 연상 기호(Mnemonic)를 붙이면 훨씬 작성하기 편하고 가독성도 좋아지는데(물론 어디까지나 기계어와 비교했을 때…), 이를 어셈블리(Assembly)라고 한다.
어셈블리는 언어로 불리지만 기계어와 1:1로 대응한다는 점에서 본질적으로는 표기법(Notation)에 가깝다. 어셈블리 표준은 다양한 CPU 아키텍처 간 호환을 위해 반드시 필요한 것 같은데 왜 없는지가 궁금해졌는데, 찾아보니 표준은 있지만 준수되지는 않는다고 한다.
Project
이번 과제는 2장에서 구현해본 ALU에서 실행이 가능한 16비트 명령어를 사용하는 간단한 프로그램을 작성해보는 것이었다. 메모리의 주소 공간을 15비트로 정의하면서, 2^15 = 대략 32K개의 레지스터를 사용할 수 있게 되었지만, 16비트 명령어에 15비트짜리 메모리 주소를 사용할 수가 없으므로 주소를 통한 메모리의 접근은 A 레지스터의 값을 주소로 사용하는 방식을 채택하였다. 또, 특정 주소 구간의 레지스터를 모니터 출력(0x4000 ~ 0x5999)과 키보드 입력(0x6000)으로 할당해서 입/출력 장치와의 상호작용도 가능했다.
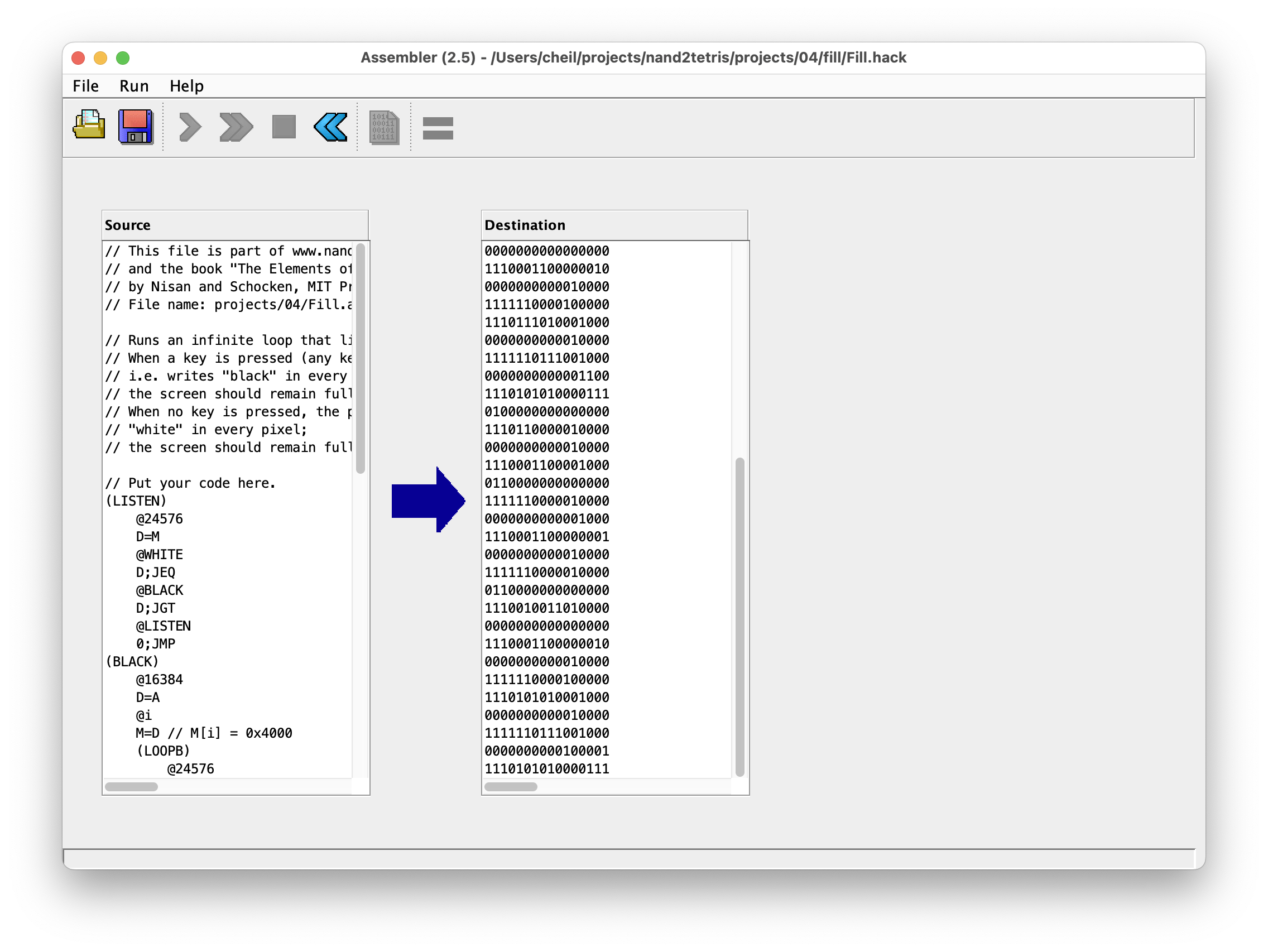
작성한 프로그램을 위와 같이 assembler를 통해 .hack 확장자를 가진 binary 파일로 변환하였다.
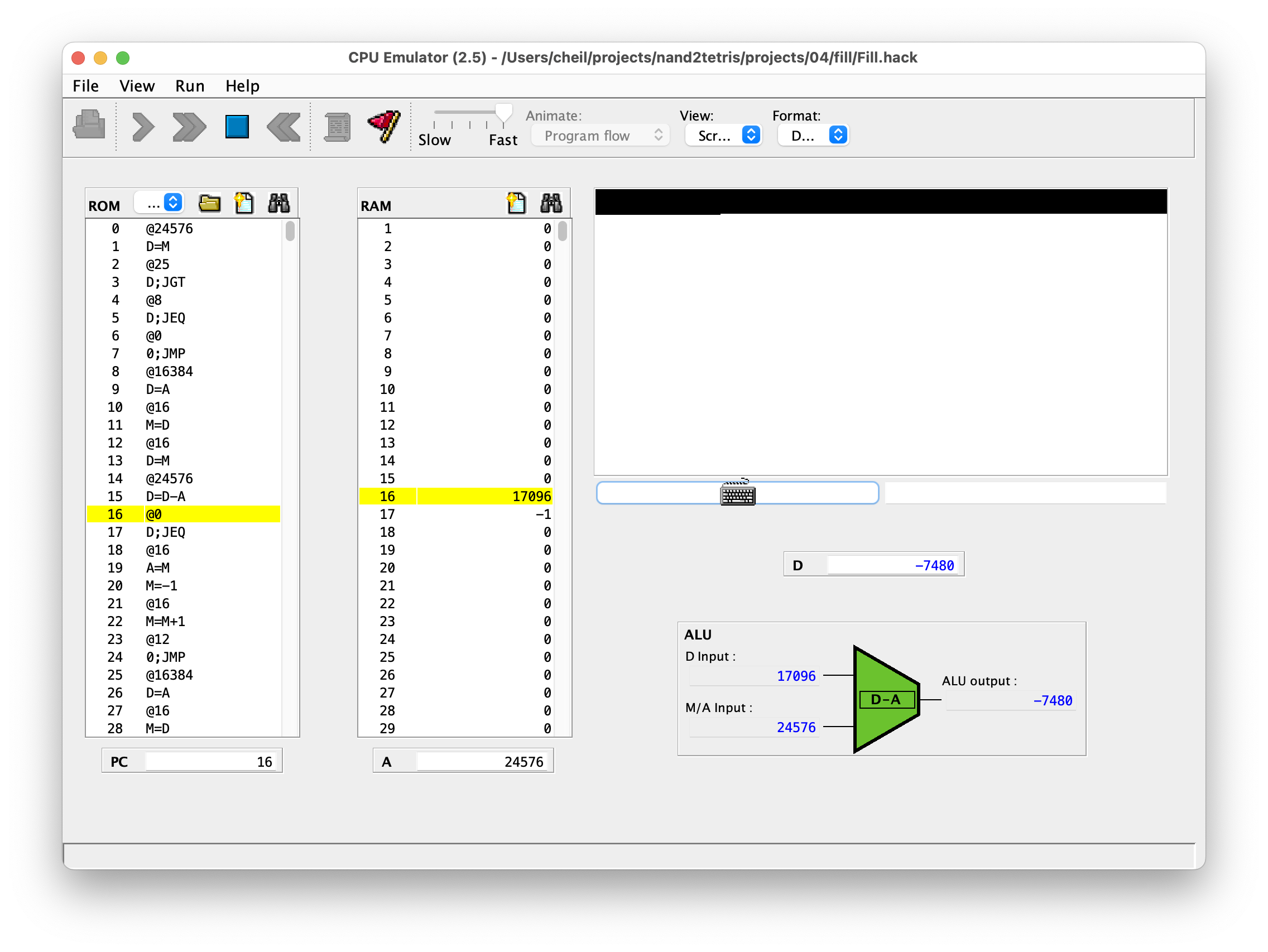
binary 파일을 시뮬레이터로 실행하면서 키보드의 입력에 따라 모니터의 픽셀이 검은 색으로 채워져 나가는 과정을 확인할 수 있다. 문제는 과제에서 제시한 대로 모니터 전체를 검은 색으로 채우기 위해서는 레지스터 8192개의 값을 -1로 설정해야 했는데, 가장 빠른 속도로 프로그램을 설정하여도 몇십 분은 걸릴 듯하여 포기하였다. (변명하자면 어차피 종료조건도 없는 무한 루프이기 때문에 더 붙잡고 확인할 것도 없었다.)
컴퓨터 구조에 대한 이해가 필요하다는 생각에 책을 샀지만, 이전에 3장의 벽에 부딪혀 한번 중단했었다. 책 자체는 정말 좋은 내용이고, 심지어 책의 구조가 모든 내용을 스스로 구현하는 과제 형태로 되어 있어서(테스트 케이스, 스크립트, 툴까지 제공한다) 한번 훑고 이해했다 착각하고 넘어갈 수가 없다. 현업에서 직접 써먹을 일은 거의 없겠지만, 항상 완벽하게 이해하고 싶었던 내용이라서 언젠가는 반드시 모든 과정을 수행하리라 다짐했었다.
책에서 다루는 내용은 아래와 같다.
불 논리
불 연산
순차 논리
기계어
컴퓨터 아키텍처
어셈블러
가상 머신 I: 스택 산술
가상 머신 II: 프로그램 제어
고수준 언어
컴파일러 I: 구문 분석
컴파일러 II: 코드 생성
운영체제
01. 불 논리
하드웨어 중에서도 가장 기초적인 칩을 소프트웨어로 구현해본다. 가장 기초가 되는 NAND 게이트를 활용하여, AND, OR, NOT 등의 기초적인 게이트를 구현해보고, MUX, DMUX 등의 컴포넌트를 구현해보는 과정이다. 구현을 마치면 Hardware Simulator라는 툴을 통해 작성한 로직이 실제로 의도한 대로 동작하는지 테스트해볼 수 있다.
실제로 사용되는 하드웨어에서의 구현과는 차이가 크지만, 추후 더 큰 시스템을 구성해나가는 데 있어 가장 기초가 되는 컴포넌트를 실제로 만들어본다는 점에서 의미가 있고, 간단한 HDL(Hardware Description Language)과 Hardware Simulator 사용법을 이해하게 되었다.
02. 불 연산
거의 모든 연산의 기본이 되는 덧셈을 수행하는 회로(칩)을 1장에서 구현한 간단한 회로를 사용하여 반가산기(HalfAdder), 전가산기(FullAdder)를 거쳐 실제로 구현해보고, 다시 이를 활용하여 ALU(Arithmetic Logic Unit)를 만들면서 컴퓨터가 어떻게 비트를 사용하여 연산을 수행하는지를 배운다. 1장에서 구현한 MUX, DMUX같은 컴포넌트를 대체 어디에 써먹는건지 이해할 수 있게 되었다.
03. 순차 논리
첫 번째 고비였다(두 번째 고비가 언제일지는 모른다). 그 동안 구현한 논리들은 입력값에 따라 출력값이 결정되었지만(조합 논리), 데이터를 저장하는 논리의 구현을 위해서는 입력 신호 뿐만 아니라 시간의 흐름에 따라 출력이 결정되는 논리(순차 논리)가 필요하다. 물론 시간의 흐름이라는 것도 결국 주기적으로 발생하는 입력 신호로 구현되지만, 그것을 활용하여 실제로 논리를 구현하는 데에는 꽤 오랜 시간이 걸렸다.
컴퓨터는 마스터 클락이라는 장치에서 tick과 tock이라는 신호를 끊임없이 전달하면서 시간의 흐름을 시뮬레이션하며, 시스템 내부의 순차 논리를 수행하는 모든 회로는 이를 전달받아 tick 신호에 입력값을 업데이트하고 tock 신호에 이에 기반한 출력값을 출력한다.
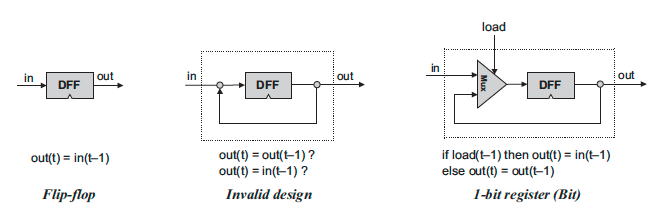
순차 논리의 핵심이 되는 회로는 DFF(Data Flip-Flop)으로, 입력값을 단위시간만큼의 지연을 거친 뒤 출력하는 논리를 수행한다. 즉, 입력값이 바뀌어도 출력값은 다음 tock 신호와 함께 갱신된다. 이 단순한 회로의 출력 핀을 다시 입력 핀에 연결한다는 아이디어가 데이터를 저장하는 논리의 핵심이다. 출력값과 입력값이 무한히 순환하면서, 데이터가 보존되는 것이다.
물론 데이터를 보존하기만 해서는 저장장치의 역할을 수행할 수 없다. 어떤 값을 보존할지 결정할 수 있어야 하는데, ‘읽기 모드’와 ‘쓰기 모드’라는 상태를 부여함으로서 이를 해결하고 1개의 비트를 저장하는 간단한 로직을 구성할 수 있다.
읽기 모드: 입력값과 상관없이 이전 사이클의 출력값을 다시 출력
쓰기 모드: 다음 사이클에 현재 입력되는 값을 출력
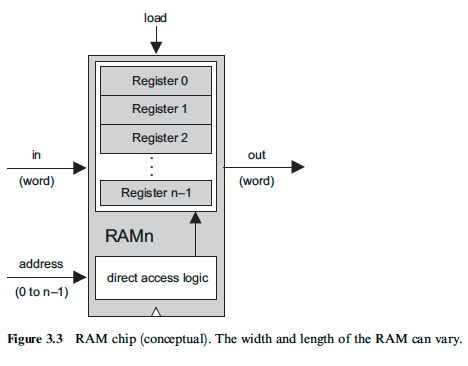
이를 확장하여 원하는 크기의 데이터를 저장할 수 있도록 구성한 것을 레지스터(Register)라고 부르며, 레지스터의 크기는 해당 시스템이 다루는 데이터 크기의 기본 단위가 되어 이를 워드(word) 크기라고 부른다.
레지스터를 확장하면 비로소 RAM(Random Access Memory)이 되는데, 말 그대로 Random Access가 가능한 메모리라는 의미이다.
‘메모리’: 메모리 기능은 결국 수많은 레지스터의 집합으로 구현되며, 따라서 RAM의 크기는 (레지스터의 크기)*(레지스터의 개수)가 된다.
‘Random Access’: 이는 특정 레지스터의 주소 정보를 사용하여 해당 레지스터의 값에 즉시 접근이 가능하다는 의미이다. 메모리 구조를 순차적으로 탐색하는 것보다 빠른 입/출력이 가능하기 때문에 이는 매우 유용하며, DMUX/MUX를 계층적으로 사용하여 이를 구현할 수 있다.
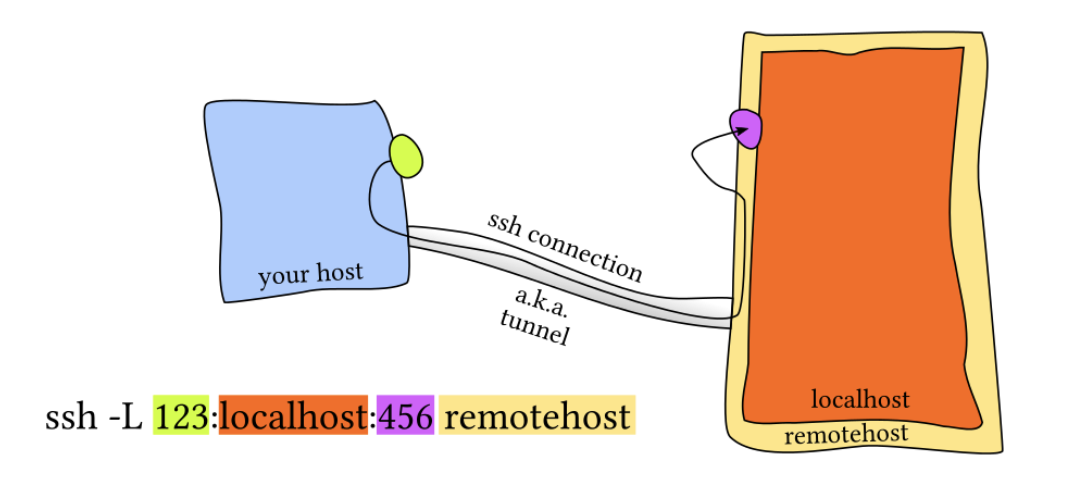
위 예시는 target server를 localhost, 즉 자기 자신(gateway server, SSH server, 1.2.3.4)으로 지정한 경우이다. 이 때는 접근이 허용된 어느 호스트(자기 자신을 포함하여)에서든 프로세스를 실행한 클라이언트의 123번 포트(아래 이미지의 your host:123)로 요청을 보내면, 해당 요청은 ssh 터널을 통해 root@1.2.3.4 –> 127.0.0.1:456 연결로 forward된다.
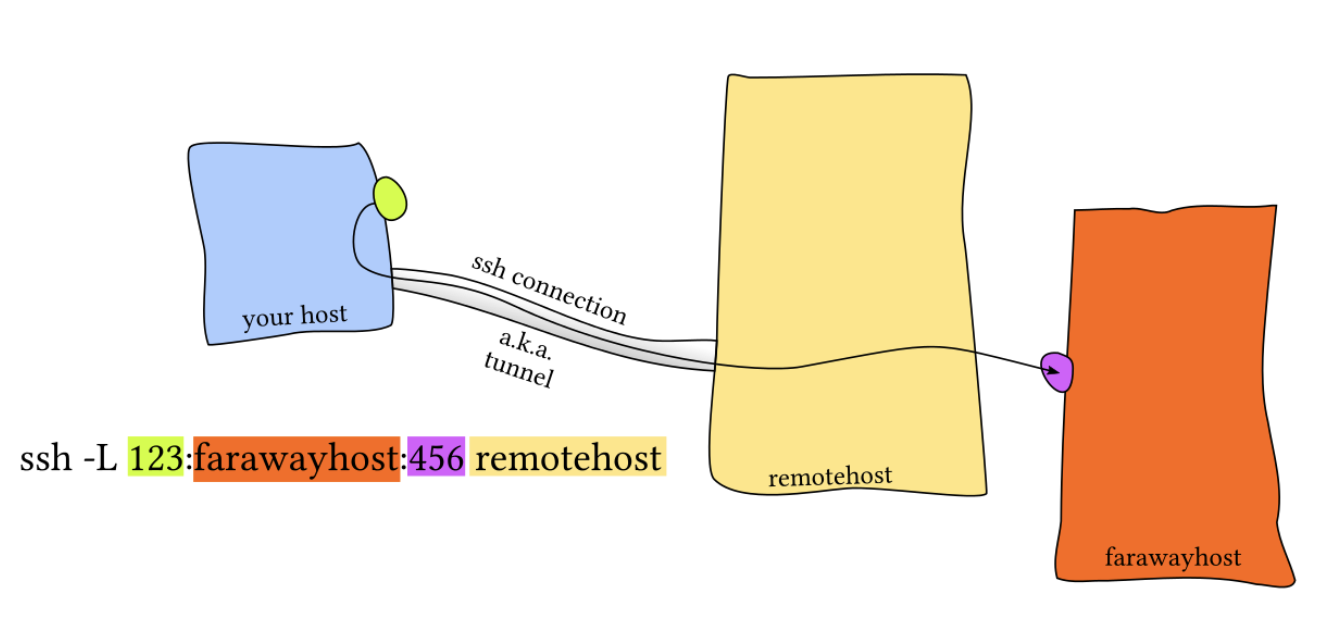
반면 위와 같이 target server를 다른 farawayhost로 지정하여 포트 포워딩을 실행할 경우, 클라이언트의 123번 포트로 보내진 요청은 ssh 터널을 통해 1.2.3.4 –> farawayhost:456으로 forward된다.
즉, Local Port Forwarding은 아래와 같은 기능을 수행한다.
<some_host> –> <client_host>:<client_port> 를 아래 연결로 forward한다. <remote_host> –> <target_host>:<target_port>
Local Port Forwarding의 이점
Local port forwarding을 통해, 불특정 다수(<some_host>)의 <target_host>:<target_port>로의 접근 제어를 <client_host>:<client_port>로의 접근 제어를 통해 관리할 수 있다. 즉 <target_host>:<target_port>는 <remote_host>(Bation Host의 역할을 수행)로부터의 접근만 허용하면 된다는 점에서 <target_host>를 보다 안전하게 관리할 수 있고, 보안/시스템적 제약 사항을 우회하는 데에도 자주 쓰인다. 컨테이너 기반 환경에서는 특히 이러한 Local Port Forwarding을 요긴하게 사용할 수 있다.
HTTP는 무상태(stateless) 프로토콜이다. 하지만 클라이언트와의 상호작용을 위해서는 서버가 클라이언트(사용자)의 상태(state)를 알 수 있어야 한다. 이를 위해 등장한 기술이 몇 종류 존재하는데, 쿠키, 세션, 웹 스토리지가 그것이다.
쿠키(Cookie)
쿠키는 서버가 클라이언트를 식별하고 클라이언트의 상태를 저장하기 위해 사용하는, 클라이언트에 대한 정보를 저장한 파일이다. 브라우저는 서버의 응답으로부터 쿠키를 전달받아 클라이언트 환경에 key-value 형태로 저장하였다가, 추후 HTTP 요청 시 해당 도메인으로부터 등록된 모든 쿠키를 요청과 함께 전달한다.
클라이언트 입장에서, 쿠키에 자신의 정보가 저장되는 것은 탈취당할 요소를 추가하는 것이므로 보안적인 위협이 된다. 반면, 쿠키를 관리/전달하는 주체는 클라이언트이므로 클라이언트 쪽에서는 이를 얼마든지 위/변조하여 서버에게 전달할 수 있고, 따라서 서버 입장에서도 클라이언트가 전달하는 쿠키가 보안적 위험 요소로 작용할 수 있다.
위와 같은 단점이 존재함에도 불구하고, 쿠키는 여전히 널리 사용된다. 서버가 클라이언트를 식별하고 클라이언트의 상태에 따라 동작하기 위해서는 클라이언트의 정보가 반드시 어딘가에는 저장되어 있어야 하므로, 이를 위한 가장 간편한 해결책인 쿠키는 보안에 민감한 정보가 아닐 경우에 한해 가장 먼저 고려할 수 있는 수단이다.
세션(Session)
위에서 쿠키 방식의 단점 중 하나는, 클라이언트 쪽에서 위/변조 또는 탈취한 쿠키를 사용할 경우, 서버 쪽에서 이를 탐지하고 해당 요청을 거부할 수 없다는 것이었다. 따라서, 그런 중요한 정보를 클라이언트 쪽에서 전달하는 대로 믿지 않고 서버에서 직접 사용자의 정보를 관리하는 해결책을 떠올릴 수 있고, 이를 일반적으로 세션 방식이라고 부른다. 다만 앞서 설명한 것처럼 HTTP는 stateless 프로토콜이므로 서버에서 일방적으로 클라이언트를 식별할 수 있는 방법은 없다. 따라서, 서버에 필요한 정보를 저장하여도 해당 정보와 그 주인(특정 클라이언트)를 매칭시키기 위해서는 클라이언트를 식별하기 위한 식별자 정보가 필요하고, 이를 위해 서버는 클라이언트 식별자로 사용할 수 있는 쿠키를 발급한다.
즉 쿠키 방식과 세션 방식이라고 흔히들 말하는 것에 반해, 엄밀히 따지자면 쿠키와 세션은 대립되는 선택지가 아니다. 세션 방식에서도 쿠키를 사용하기 때문이다. (쿠키를 사용하지 않는 경우도 있다고 하나, 쿠키를 사용하여 세션을 관리하는 방식이 가장 널리 쓰인다고 한다.) 하지만 세션을 사용한 사용자의 인증은 중요한 정보가 서버 측에 저장되어 불특정 클라이언트로부터의 위/변조가 어렵고, 클라이언트의 정보가 탈취당한다 하여도 세션이 만료된다면, 즉 클라이언트의 브라우저가 종료되거나 서버 쪽에서 설정한 세션 시간이 경과되면 해당 값은 사용할 수 없는 값이 되어버리므로 비교적 안전하다.
물론 브라우저가 종료되면 사용자의 정보는 모두 사라지는 점은 때로는 단점으로 작용하여, 이를 유지하기 위해 쿠키를 사용하여야 할 때도 있다. 또 대규모 시스템의 경우, 가용성을 확보하기 위해 여러 대의 서버를 사용하여 부하를 분산하게 되는데, 이러한 경우 한 클라이언트가 보내는 연속적인 요청을 한 서버가 맡아서 처리하지 않으면 사용자가 시스템을 정상적으로 사용할 수 없으므로, 세션 정보만을 처리하는 별도의 서버를 분리하여 운영하기도 한다.
웹 스토리지(Web Storage)
웹 스토리지는 비교적 최근에 등장한 기술로 HTML5 표준에서 정의되었으며, 쿠키와 유사하면서도 장/단점이 존재하지만 쿠키의 단점을 보완해줄 수 있는 기술이다. 웹 스토리지는 만료 시간이 없는 로컬 스토리지와 탭 단위 휘발성을 갖는 세션 스토리지로 구분되어 데이터의 용도에 따라 저장 장소를 선택하여 데이터의 생애 주기를 보다 효과적으로 관리할 수 있어 보다 안전하다. 또, 존재하는 모든 정보가 매번 무조건 전송되는 쿠키와 달리, 웹 스토리지에 있는 데이터 중 어떤 데이터를 전송할 지 선택할 수 있으며, string값만 저장할 수 있었던 쿠키와 달리 Javascript 객체를 저장할 수 있게 되었다는 점도 보다 다양한 방식으로 HTTP를 사용할 수 있는 여지를 준다.
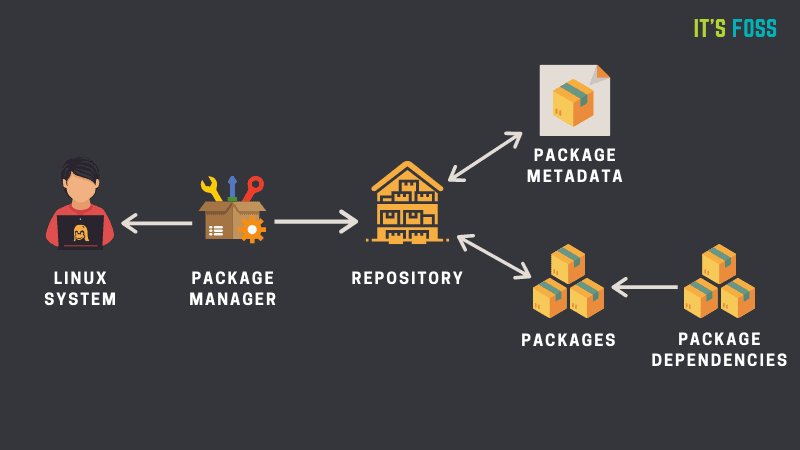
패키지는 바이너리 실행 파일들과 그 메타데이터(configuration 파일, dependency 정보)의 모음이며, 일반적으로 DEB(데비안 계열), RPM(레드햇 계열) 등 다양한 아카이브 파일 형식으로 배포된다. 패키지 매니저는 아카이브 파일을 열고 지정된 위치에 바이너리 실행 파일을 위치시키고, 그 파일이 어떤 패키지에 속하는지 파악해 두었다가 패키지를 삭제할 때 이를 삭제한다.
또, 패키지 매니저는 아래와 같은 기능을 수행하여 패키지 관리를 용이하게 해준다.
패키지 의존성 관리: 패키지 간 의존 관계를 분석하여 어떤 패키지를 설치/제거할 경우 해당 패키지가 의존하는 다른 패키지들 역시 설치/제거하여 패키지 간 의존 관계를 사용자가 직접 관리하지 않아도 효과적으로 패키지를 사용할 수 있게 한다.
패키지 버전 관리: 설치된 패키지들 중 리포지토리에 사용 가능한 업데이트가 있는 패키지가 있는지 확인하고 필요 시 업데이트하는 역할도 수행한다.
Repository
리눅스 환경에서, 패키지 매니저가 설치 대상 패키지를 가져오는 가장 보편적인 방법은 리포지토리(여기서의 리포지토리란 소프트웨어 리포지토리로, git이나 SVN같은 VCS에서 사용하는 리포지토리와는 다른 개념이다.)에서 원하는 패키지를 가져오는 방식이다. 각 리눅스 배포판마다 실행이 가능한 패키지를 제공하는 리포지토리를 운영하므로, 이를 활용하면 사용자는 편리하게 환경에 맞는 패키지를 설치/관리할 수 있다. 만약 리포지토리에서 제공하지 않는 소프트웨어를 설치하여야 할 경우, 사용자는 패키지 매니저라는 툴이 존재하지 않던 시절처럼 직접 자신의 환경에서 실행이 가능하도록 소스 파일을 빌드하고 환경을 구성하여야 한다. 여기서 말하는 환경 구성은 소프트웨어 의존 요소의 관리, 바이너리 파일의 위치 지정 등을 포함하며, 이에 추가로 구성 스크립트나 makefile등을 사용하도록 설계된 소프트웨어도 있을 것이다. 이는 굉장히 번거로운 일이며, 설치한 패키지가 많을수록 그 관리의 복잡성은 증가하고 문제 발생의 여지도 크다.
오랜만에 블로그에 포스트를 작성하고 블로그를 둘러보니, 이전에 작성한 불필요한 포스트가 보였다. 이를 로컬 디렉토리에서 삭제한 후, 블로그에 반영하기 위해 리포지토리 main 브랜치에 push하였다. 리포지토리는 Travis CI를 통해 빌드/배포 자동화가 설정되어 있으므로, 여느 때와 같이 빌드/배포 작업이 진행될거라 기대했지만, 빌드가 실패했다는 메일을 받게 되었다. 지난 11월에 블로그 프레임워크를 Hexo로 바꾸면서, Hexo 튜토리얼 문서를 보고 그대로 따라한 뒤(https://bastionsofwill.github.io/2021/11/17/hexo-travis-ghpage) 처음 겪는 빌드 실패여서 당혹스러웠으나, 몇 시간 전에 성공한 것이 실패한 이유는 당연히 안 해본 짓(포스트 삭제)을 했기 때문일 것으로 추정하고 해결을 미뤘다. 하지만 빌드 실패 결과를 살펴본 결과, 문제는 다른 곳에 있음을 알 수 있었다.
Worker information (생략) Build system information (생략) $ git clone --depth=50 --branch=main https://github.com/bastionsofwill/bastionsofwill.github.io.git bastionsofwill/bastionsofwill.github.io
Setting environment variables from repository settings $ export GH_TOKEN=[secure]
$ yarn --frozen-lockfile hexo generate (생략) The command"hexo generate" exited with 0.
store build cache changes detected (content changed, file is created, or file is deleted):\n/home/travis/.npm/_logs/2022-06-09T17_42_37_173Z-debug-0.log\n changes detected, packing new archive uploading main/cache--linux-xenial-e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855--node-16.tgz cache uploaded
$ rvm $(travis_internal_ruby) --fuzzy do ruby -S gem install dpl Installing deploy dependencies ERROR: Error installing dpl-pages: The last version of multipart-post (>= 1.2, < 3) to support your Ruby & RubyGems was 2.2.0. Try installing it with `gem install multipart-post -v 2.2.0` and then running the current command again multipart-post requires Ruby version >= 2.6.0. The current ruby version is 2.4.5.335. Successfully installed public_suffix-3.0.3 Successfully installed addressable-2.8.0 /home/travis/.rvm/rubies/ruby-2.4.5/lib/ruby/site_ruby/2.4.0/rubygems/core_ext/kernel_require.rb:54:in `require': cannot load such file -- dpl/provider/pages (LoadError) from /home/travis/.rvm/rubies/ruby-2.4.5/lib/ruby/site_ruby/2.4.0/rubygems/core_ext/kernel_require.rb:54:in `require' from /home/travis/.rvm/gems/ruby-2.4.5/gems/dpl-1.10.16/lib/dpl/provider.rb:93:in `rescue in block in new' from /home/travis/.rvm/gems/ruby-2.4.5/gems/dpl-1.10.16/lib/dpl/provider.rb:68:in `block in new' from /home/travis/.rvm/gems/ruby-2.4.5/gems/dpl-1.10.16/lib/dpl/cli.rb:41:in `fold' from /home/travis/.rvm/gems/ruby-2.4.5/gems/dpl-1.10.16/lib/dpl/provider.rb:67:in `new' from /home/travis/.rvm/gems/ruby-2.4.5/gems/dpl-1.10.16/lib/dpl/cli.rb:31:in `run' from /home/travis/.rvm/gems/ruby-2.4.5/gems/dpl-1.10.16/lib/dpl/cli.rb:7:in `run' from /home/travis/.rvm/gems/ruby-2.4.5/gems/dpl-1.10.16/bin/dpl:5:in `<top (required)>' from /home/travis/.rvm/gems/ruby-2.4.5/bin/dpl:23:in `load' from /home/travis/.rvm/gems/ruby-2.4.5/bin/dpl:23:in `<main>' failed to deploy
에러가 난 부분을 보면, deploy dependencies를 설치하다가 dpl-pages에서 에러가 발생했고, multipart-post가 Ruby 2.6.0을 요구하는데 현재 버전이 2.4.5.335인 것이 문제로 보인다.
errored?
먼저 Travis CI가 동작하는 과정에 대한 간략한 이해가 필요하다. Travis CI가 수행할 작업을 정의하는 구조는 phase -> job -> stage -> build로, 하나의 job은 아래와 같은 phase로 구성된다.
before_install
install: dependency의 설치
before_script
script: build script 실행
before_cache(OPTIONAL)
after_success/failure
before_deploy(OPTIONAL)
deploy(OPTIONAL)
after_deploy(OPTIONAL)
after_script
stage는 이러한 job들이 병렬로(in parellel) 실행되는 그룹을 말하며, build는 이러한 stage들이 순차적으로 실행되는 그룹을 말한다.
하나 이상의 job이 실패할 경우 그 job이 속한 빌드는 비정상(break)이 되며, 비정상 빌드는 아래 세 가지 키워드 중 하나로 표시된다.
errored: before_install, install, before_script, before_deploy phase가 정상적으로 종료되지 않을 경우(non-zero exit code) 발생
failed: script phase가 정상적으로 종료되지 않을 경우 발생
canceled: 사용자에 의한 취소 after_success/failure, after_deploy, after_script의 exit code는 빌드 결과에 영향을 미치지 않지만, 타임아웃이 발생했을 경우 빌드 결과는 failed로 표시된다.
즉, 위의 job log를 살펴본 결과, hexo generate라는 1줄짜리 스크립트가 실행되는 script phase까지는 무사히 실행되었으나, before_deploy phase에서 deploy dependency를 설치하다가 오류가 나서 build가 errored로 표시된 것임을 확인할 수 있었다.
dpl-pages와 multipart-post
에러가 난 지점에 대한 감은 잡을 수 있었다. 하지만 여전히 문제에 대한 지식은 많이 모자란 상황이다.
1 2 3 4
Installing deploy dependencies ERROR: Error installing dpl-pages: The last version of multipart-post (>= 1.2, < 3) to support your Ruby & RubyGems was 2.2.0. Try installing it with `gem install multipart-post -v 2.2.0` and then running the current command again multipart-post requires Ruby version >= 2.6.0. The current ruby version is 2.4.5.335.
에러 로그를 다시 살펴보면, dpl-pages를 설치하다가 에러가 발생하였고, multipart-post가 요구하는 ruby 버전이 2.6.0 이상인 것이 문제임을 알 수 있었다.
첫번째로 든 의문은, ‘dpl-pages, multipart-post는 또 뭔데?’였다. ‘배포 작업을 수행하기 위해 필요한 무언가’ 정도로만 추정이 되는 상황이었으므로, Travis CI가 배포하는 방식에 대한 지식이 필요했다.
이전에 생각없이 hexo tutorial을 복붙하면서, 나는 인지하지 못한 채 Travis CI의 GitHub Pages Deployment 기능을 사용하고 있었다.
1 2 3 4 5 6 7 8
deploy: provider:pages skip-cleanup:true github-token:$GH_TOKEN keep-history:true on: branch:main local-dir:public
위의 yml 파일이 관련 설정으로, provider: pages를 비롯한 설정을 통해 hexo generate의 결과물인 public 디렉토리 하위 파일들을 타겟 브랜치(지정하지 않았으므로 기본값인 gh-pages 브랜치)에 push하는 기능이다.
해당 기능에 대한 Travis CI 문서 확인 결과, dpl이라는 루비 코드를 사용하는 것을 알 수 있었다. 하지만 여기서 결국 dpl-pages, multipart-post에 대한 내용은 결국 찾지 못했는데, ruby에 대한 지식이 없는 상황에서 dpl의 문서에는 관련 내용이 없기 때문이다. 하지만 dpl은 rubygem으로 publish/관리되고 있다는 내용이 있었으므로, dpl, dpl-pages, multipart-post라는 gem에 대한 기본적인 정보는 찾을 수 있었다.
갈림길
1 2 3 4
Installing deploy dependencies ERROR: Error installing dpl-pages: The last version of multipart-post (>= 1.2, < 3) to support your Ruby & RubyGems was 2.2.0. Try installing it with `gem install multipart-post -v 2.2.0` and then running the current command again multipart-post requires Ruby version >= 2.6.0. The current ruby version is 2.4.5.335.
위의 메시지를 자세히 보면, 배경이 어떻든 결국 multipart-post라는 gem이 ruby 2.6.0 이상을 요구하는 반면, 환경에 설치된 ruby는 2.4.5.335 버전인 것이 문제임을 알 수 있다.
따라서 이를 해결하기 위해서는 아래 두 가지 해결책을 떠올릴 수 있다.
ruby 버전을 2.6.0 이상으로 올린다.
multipart-post의 버전을 2.2.0으로 내린다.(에러 메시지에서 권장한 방법)
두 방법 모두 Travis CI가 동작하는 환경에 대한 조작이 필요하므로, .travis.yml 파일을 건드려야 한다. 쉽게 끝날 수도 있겠지만 아닐 가능성이 더 커서 꺼려지는데, 어느 쪽이 더 쉽고 문제가 적을지를 생각했다.
1안: ruby 버전 업그레이드
2안 같은 버전 다운그레이드는 결국 문제를 나중에 터지도록 미루는 것이라는 생각이 들었다. 또 몇 시간 전까지도 잘 동작하다가 에러가 발생한 상황이어서, ruby 2.6.0은 비교적 최근에 릴리즈된 버전일 것이라 예상했고, 새로운 버전을 쓰면 좋을 것이라는 생각이 들었다. 하지만 확인 결과, ruby 2.6.0의 릴리즈 일자는 2018년 말이고 2.6.10도 이미 지원 종료(EOL)되었다. 이를 알게 되니 ‘아직도 몇년 전 버전의 루비를 사용하는 것을 보니 역시 고수들도 dependency는 함부로 건드리기 어렵구나’ 라는 생각에 갑자기 버전 업그레이드가 부담스러워졌다. 애초에 에러 메시지에서도 multiport-post의 버전을 낮출 것을 권장하였으니, 2안에 대해 알아보는 것이 좋을 것 같다.
2안: multipart-post 버전 다운그레이드
몇 시간 전만 해도 되던 걸 안 되게 만든 주범으로 추정되는 multipart-post는 직접적으로 확인할 수는 없었지만 에러 메시지를 통해 추정하면, 몇 시간 새 2.2.0 이후 버전이 적용되면서 Travis CI의 가상환경에서 사용되던 ruby 버전과 충돌을 일으킨 것으로 추정된다. 확인을 위해 rubygems.org에서 multipart-post를 찾아본 결과, 2022년 6월 9일에 릴리즈된 2.2.2 버전은 ruby 2.6.0 이상을 요구하였다. 하지만, 그 다음날에 릴리즈된 2.2.3 버전은 ruby 2.3.0 이상으로 요구 조건이 완화되었다. 즉, multipart-post 2.2.3 버전을 사용하면 현재 버전인 2.4.335도 문제없이 사용이 가능한 것이다.
고마워요, ioquatix!
따라서, multipart-post를 관리하는 고수님들의 빠른 조치(https://github.com/socketry/multipart-post/pull/95) 덕에, 나는 아무 것도 하지 않아도 저절로 문제가 해결되는 기쁨을 누렸다. 실제로 아무 조치 없이 빌드를 재실행한 결과, 빌드에 성공하였다. 내가 Travis CI가 사용하는 ruby의 버전을 지정하는 방법을 배워야 하는 사태가 발생하기 전에 Travis CI팀이 default ruby 버전을 계속 업그레이드 해주길 바라면서, 또 이 포스트의 속편을 바로 작성해야 하는 일이 없기를 바라면서 성공한 빌드 로그로 포스트를 마친다.